MapStory Health & MapStory Epidemiology
Good health is the most important thing in one’s life, so it should be a no-brainer that we should map it. But like my own health, I only really started taking it seriously as an afterthought. Actually, one of the interns working with me, Ravi Bhavirisetty, expressed interest in mapping health issues, and we started looking into things. We quickly found a lot of data that we will use to produce pilots to launch MapStory Health and MapStory Epidemiology (a subcategory of MapStory Health), which will eventually map all of the world’s health issues. Maps are of utmost importance for the study of health problems, and mapstories will take things to a whole new level. Imagine being able to see everyone in the world who have a particular health problem and its severity, from its first recorded case – dots popping up for each person, and colors darkening for the density of prevalence. Of course this has massive ethical issues – someone’s health should be private in many circumstances, and areas of a city or countryside, or even an entire part of a country or part of the world can be stigmatized where the prevalence is higher. It is of course a trade off, but of course beyond a certain point, mapping health is immensely necessary and beneficial for addressing the problem.
Dr. Snow – Maps and the Founding of Modern Epidemiology
John Snow, one of the fathers of modern epidimiology, in fact launched his work and much of the modern study of disease by producing the map you see below (along with a TED talk about the story), that not only provided evidence that a cholera outbreak was water-borne, but the exact point from which it was coming. With the help of Henry Whitehead, a local reverend, he mapped each incidence of a sudden cholera outbreak in 1854 (one of many you can see in a mapstory), which was killing dozens of people over the course of a few days along a single street in London. He mapped all the water pumps in the neighborhood, and saw that the outbreak was happening closely clustered around a single pump. The common belief was that the foul air of industrial Britain was causing the disease to spread, and people in the area has mostly fled. In a heroic act, he went into the community, with all its foul stench, and in a riteous act of public vandalism, broke the handle on the pump. The outbreak stopped.
{kind=link}
And things changed forever, an effect that is happening everywhere – I read another fascinating explanation of how the adhoc way they took care of the problem led first to massive centralized water distribution, which caused other health and environmental problems, which in turn created a massive centralized sewage and runoff system, which cause more to this day (more to come in another piece of writing some day on the practical need for distributed water infrastructure).
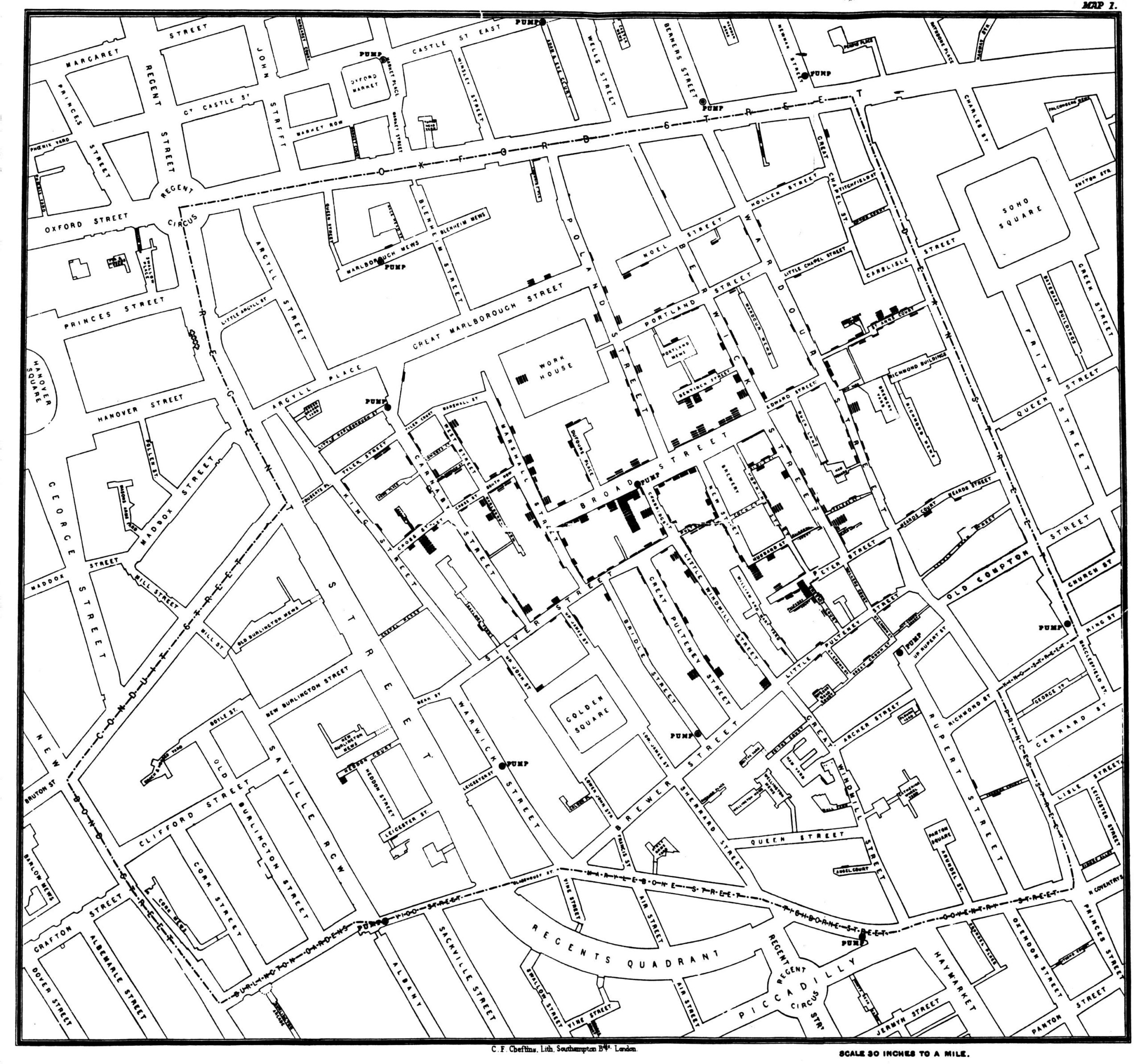 |  |
| A famous example of spatial analysis in the analog days (click to enlarge). | The site of the original pump; a public memorial celebrating an act of public vandalism. |
Dr. Hotspot – Taking care of the community
Mapping even general health issues is immensely useful when mapping precisely, by individuals. Another fascinating example I learned about hotspot analysis was through a short Frontline episode that you can see below – Dr. Jeffrey Benner, dubbed “Dr. Hotspot” in The New Yorker, mapped the health of Camden, New Jersey, which is in the top 3 poorest cities in the US. After seeing a young man shot and giving him CPR while a dozen cops stood around, Benner got angry; as he tried to address what happened, he realized there were deep systemic problems in how the police were handling their jobs. The whole story as written an interview with Frontline is even more epic than what they show in the video, much like the story of Dr. Snow. Like Snow, who tried to work with local authorities, Benner was found to be irritating and was ignored initially. He tried to work with the police department to map crime, but they were not willing to make the effort. Luckily, as a doctor, he was able to access hospital records, where he submitted a proposal and with a student, dug through all the medical reports and bills of all of the accidents and injuries, and built up an amazing dataset. He documented that 1% of patients had 30% of the medical bills, and were repeatedly coming to the E.R. when they needed primary care and follow-ups. Benner built a group of people called the Camden Coalition that did exactly that, getting to know patients and taking care of them more as a community, and at the time of the interview, at an annual cost of $225,000 for the team, they were able to reduce the costs of care for the most expensive patients by 40-50%. The most expensive patient alone had over $600,000 in medical bills and 43 of the patients had bills that totaled $3 million, all over a 5-year period. In the Frontline short, they show one patient that lived in a house with his family, where he suffers from asthma and epilepsy, and the building is full of black mold. They were working with contractors to remove the mold, and following up with him, and reduced his visits to the E.R. from 35 visits in 6-month period to 2 visits. The man was very appreciative of the coalition, and was obviously willing to show his face on camera openly. Studies have since found that the same problem has been found to be replete everywhere throughout the American medical system. Now, data revealed things with extraordinary precision, but it would be naive to say that was the root of the problem – it is in fact the administration of people as numbers rather than relationships that causes much of the problem in the first place; Benner and his team addressed the problem as a community, which all healthcare should be. But either way, regardless of how much you improve everything else, data is clearly immensely useful.
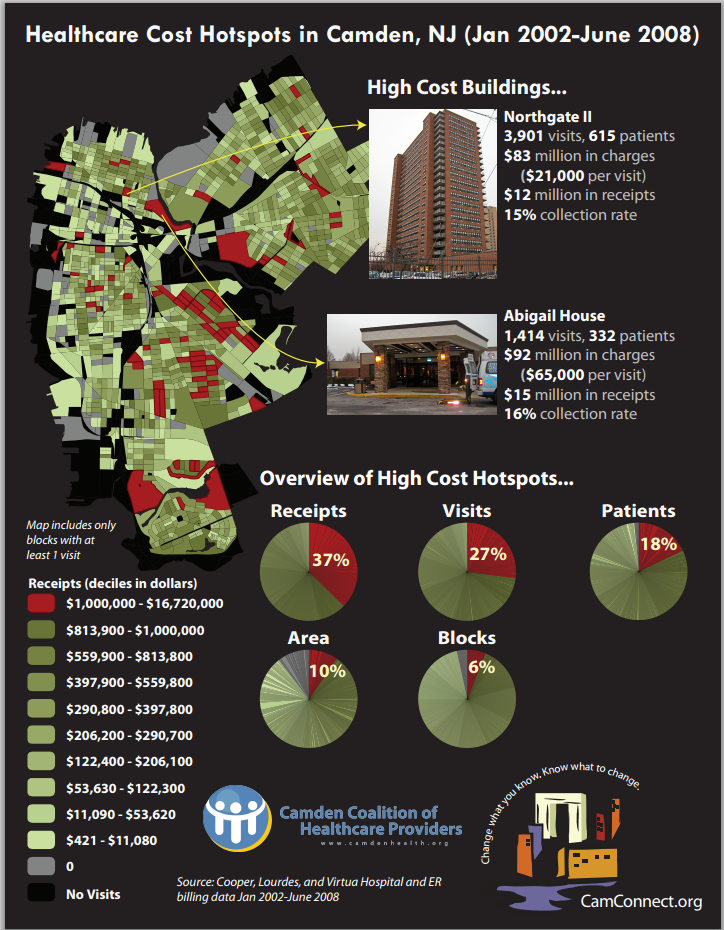

Mapping All Individuals, Available to Everyone?
The thing about Benner and Snow is that they were amateurs. Professionals often tout their authority and expertise as reasons for their access to information, but they fail to realize that the people they revere as the “fathers” or “mothers” of their profession or method of analysis were amateurs that created their expertise when it didn’t exist in the first place – in the area they founded, they were by definition not professionals. And yet data is often only available to professionals or elites. In fact, Benner and Snow were like anyone who stumbles across information when taking an interest in a subject – they played around with data, and produced profound results. Imagine if non-elites had access to data. Benner happened to be a doctor and more easily gain access to data, who also happened to care. If everyone had access, it would increase its use and our understanding vastly, by orders of magnitude, as people would not have to gain access every time through a complex process of gaining trust. Another very fundamental thing that people seem to not understand with data is that if there is any barrier at all, that barrier will rarely if ever be crossed. In fact, the majority of the time, people stumble upon data when it is simply there – they would not make any effort if they didn’t know what was behind the barrier in the first place. Imagine all the times you have stumbled across something by flipping through a book or articles on Wikipedia or a news site, or you explored the world in google earth – imagine if all of sudden one of the sites said “you must submit a proposal to receive access”. I would suspect that the number of users and the knowledge it provides people would drop to to a tiny fraction of what it was before, only by those who are really eager to do research with a strong purpose and the time to do it.
Another aspect of elite access is that time has shown that again and again, elites have failed – the response of the US government to the AIDS epidemic was to completely ignore it and for many politicians a “gay cancer” that the people who were suffering from it rightfully deserved. The AIDS agenda was actually formed and pushed in large part by the communities that it was affecting – I strongly recommend two movies on this, How to Survive a Plague and The Dallas Buyers Club. I watched another Frontline on microbial resistance, and the lack of effort in addressing resistance was frightening – antibiotics research had been gutted completely in both private industry and public insitutions, and there was no intellectual base and in fact no one dealing with the issue systematically. People seem to think that authorities are infinite in delivering the responsibilities they are charged with, when it takes people who care, which can never be unconditionally delegated to an administrative body.
But communicable diseases have a double-edged sword of social stigmatization – anyone who knows the first things about the history of AIDS can tell you that revealing or risking the identity of a person, or even an area, can have serious consequences – in the early days of AIDS, when people did not understand it, a diagnosis was a social death sentence – you would lose your job, your friends, your family, and people would not go anywhere near you, because they thought they could get it by touching you (again, see the movies mentioned above). The health benefits for people must be balanced with privacy, so where should we draw the line? I am not an expert on this issue, but with the little I have seen, it depends on the disease and social issues around it. But bottom line, we can aggregate and map with total precision for all data that is recorded, and we probably should in most cases; the degree of precision available to anyone outside of trusted circles is another question.
Mapping for the Masses
So what is out there, and how do we achieve this? I have come across some centralized sources of data, such as statistics at the Center for Disease Control (CDC). I am trying to find all I can, and have been focusing on communicable diseases, since that is an issue that people take more seriously as a public health and security risk. I’ve been focusing on microbial resistance, tuberculosis, and AIDS.
*The first site Ravi found ranks health issues by county, from obesity to overall health rankings. Ravi is processing the dataset so that we can map all of the health issues using a single table in MapStory.
*For tuberculosis, when I contacted the CDC about their tuberculosis data, they said that they only have data at the state level, and they replied that they only receive numbers from states. If you click on each state in the list they sent, most of them seem to have a list of cases by county going back 10 years. It would be great to create a mapstory of TB going back as far as possible in the US. The bizarre thing is that the data is all over the place. This is the problem that hopefully sites like MapStory will gradually solve – why put your data on your own hard drive, when you can put it all in one place online? I may email a few states and see how far back I can get their data. If a complete mapstory were created, then we can work with them to have their data automatically added to mapstory, as we are going to be doing with other pilot projects.
*For bacterial resistance, I found one some statistics at the CDC and a site that actually has great mapstories, where you can choose a pathogen or the use of an antibiotic, and slide the timeline with graphs. The data has low granularity, being at the level of states and countries. Frankly, I can’t stand seeing data at that level, it is hardly useful or even that interesting. But it’s a start, and I’ll have to see if we can get more precise data from the sources.
*For AIDS, I found a nice site called AIDSvu that collects statistics by county and for 22 cities collects data by zip code. They have agreements with state and local agencies. From experience, I can imagine that took some work and persistence. They have done the leg work, now to have the data mirrored on MapStory and over time. I wonder how difficult it would be to find data going back to the beginning of the AIDS epidemic, from the first reported cases. When that is done (not if, but when), that will be an incredible mapstory.
AIDSvu has made a leap in precision, but I’d like to experiment with greater precision. For one thing, these boundaries are not evenly populated, not by a long shot – counties range from a few people to 10 million people, and zip codes range from a few people to 100,000. The divisions of counties are simply historical vestiges, and zip codes are based on how easy it is for the post office to deliver mail. They do not exist for data.
So how can we increase precision? The rules of AIDSvu appear somewhat simple – for example: if the numerator is less than 5 (there are less than 5 people in an area) and/or the denominator is less than 100 (there are less than 100 people in a county), then all the data is suppressed. So I am thinking – if that is the threshold of reasonable privacy, can you divide up an area with 5 or more people with AIDS within an area with 100 or more people without AIDS? That would be extremely precise, and the map would be way more interesting and useful. Perhaps you would have to have some standards for minimum area as well – I can imagine that if there is a few people with AIDS in a building could give it give it unreasonable stigma (where I live, there is a dorm that at was said at one time to have its own zip code).
The problem is, the advantage of administrative boundaries and zip codes is that they hardly change, unlike other things like census tracts. Creating a mapstory of a place that is divided up that way would be interesting, but you would see the boundaries changing constantly. Perhaps one should create some sort of algorithm that divides up and combines areas based on previous boundary lines in the most optimal way (come to think of it, a mapstory of boundaries divided evenly by population would be really cool to see in itself). Either way, I can’t imagine that it wouldn’t be way more awesome to see the precision, and that it would be too chaotic to make out the changes in given areas, especially if the areas were with small numbers of people. Problem is, of course, how do you work with a given agency and adjust data without having a map of every individual? There would still be more optimal ways to divide up areas, like along neighborhood lines that divide things optimally according to population and cultural geography. And allowing people to generate a map from the underlying data without seeing the individuals can still in theory allow people to deduce where individuals live (think of a venn diagram generated until the overlaps have one person in them). I suppose I’d have to work with one, gaining access, and then deploying it. And come to think of it, an even more profound idea can develop, where data is divided according to an algorithm that becomes a standard for mapping precision.
Even with counties, or any area for that matter, drawing a boundary around an area is not the same as seeing where people live. I think that we need to start playing with how data is displayed. One absolutely incredible map I saw recently has the ultimate precision – it shows every person in the United States as a dot, colored by their race. You can zoom in on your own community and see exactly where and how densely people live, and their broad racial identities. Now, all you would have to do is take a map like that and combine it with another map, with the boundaries drawn lightly. Check out the proof of concept I made in photoshop below. It’s missing county boundaries and it doesn’t show all 300 million dots, but you get the idea. I think that it is much more descriptive spatially, especially when you look at the western half of the US.
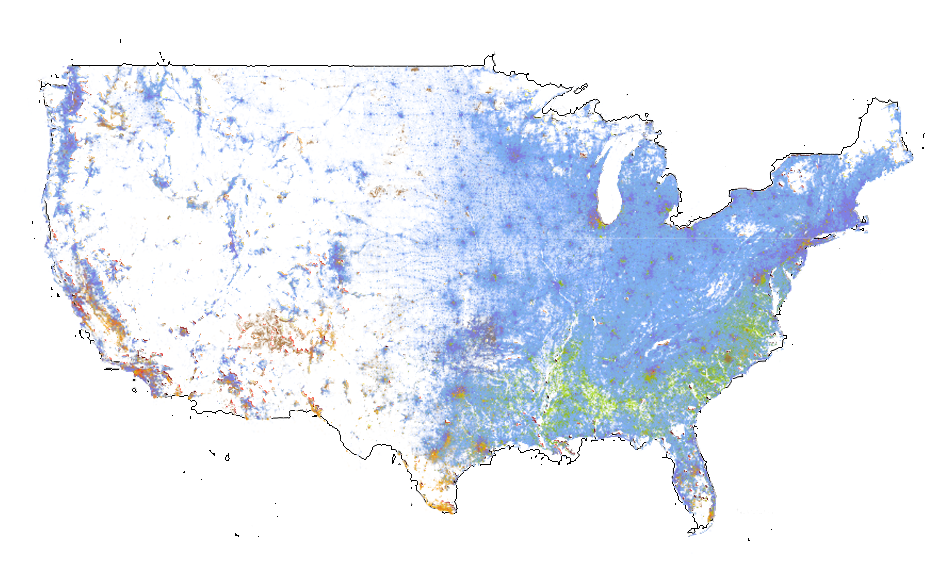

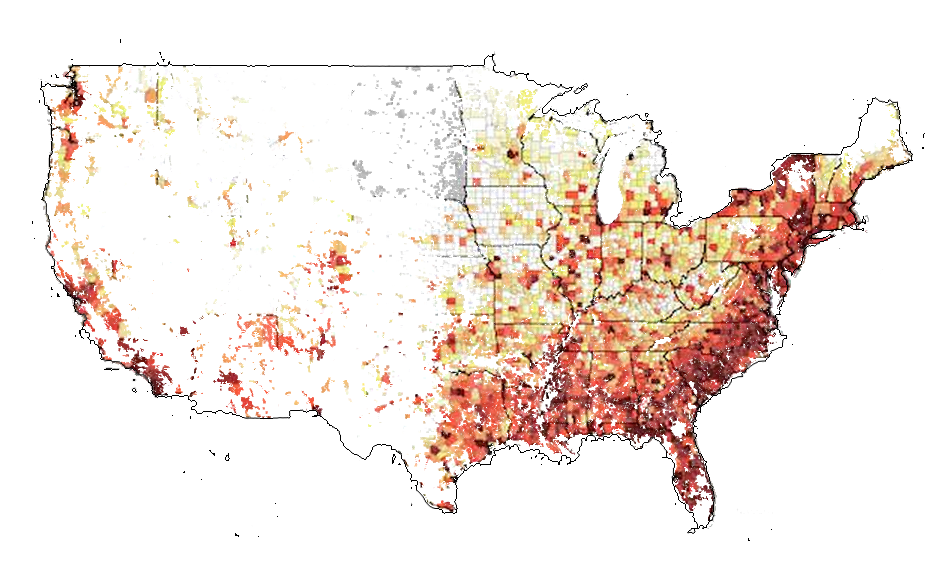
(missing county boundaries)
I think that MapStory Health will ultimately become an essential tool for tracking and understanding health issues, and MapStory Epidemiology will become a necessary security tool. Everyone will be putting their data into the commons, and see it all in one place. We just have to build on the work others are already doing and help demonstrate why that is a really good idea with some pilot projects, and work with health agencies to make it a standard practice.